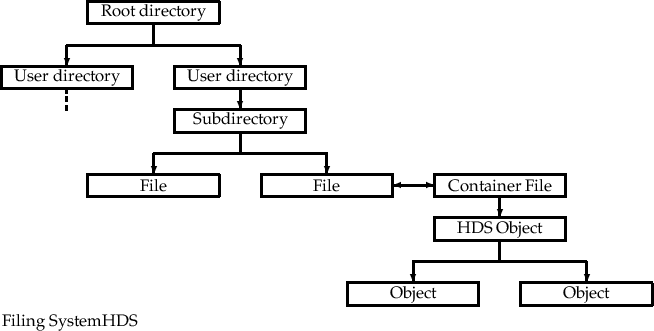
Figure 1: The relationship between a computer’s filing system and HDS.
This document is intended for those people who intend to write programs using HDS. It is tutorial in style and assumes no prior knowledge of HDS, although some knowledge of a hierarchical filing system will be helpful. Anyone who has used UNIX should understand the analogies that are drawn between directories and HDS structures.
This note mainly deals with HDS as a “stand-alone” software package. Routines which interface HDS with a particular software environment (i.e. the HDS/ADAM parameter system routines) are not considered here.1
Reference information is presented in the appendices. Appendix A gives a list of the calling sequences for the HDS routines; this will be useful to experienced programmers who just want to be reminded of the parameters required, while Appendix B gives full routine specifications for all of HDS. Appendix E describes the HDS error codes.
HDS stands for “Hierarchical Data System”. It is a flexible system for storing and retrieving data and takes over from a computer’s filing system at the level of an individual file (see Fig 1). A conventional file effectively contains an 1-dimensional sequence of data elements, whereas an HDS file can contain a more complex structure. There are many parallels between the hierarchical way HDS stores data within files and the way that a filing system organises the files themselves. These analogies will be helpful in what follows.
The advantage of HDS is that it allows many different kinds of data to be stored in a consistent and logical fashion. It is also very flexible, in that objects can be added or deleted whilst retaining the logical structure. HDS also provides portability of data, so that the same data objects may be accessed from different types of computer despite the fact that each may actually format its files and data in different ways.
1See ADAM Programmer Note 7 for a description of these routines.