
Figure 1: The serial version of the iterative map-maker. The modules within the dashed box
are part of the iteration loop, which is terminated when a convergence criterion or criteria is
met.
The iterative map-making algorithm as implemented by makemap is described in detail in [7]. Figure 1 shows the overall flow of the algorithm. Data are read from disk, prepocessing steps (such as calibration and spike detection) are applied, and then a series of models is fit to the time-stream residuals with the other best-fit models removed (initially assuming all models are zero). This procedure is iterated until a convergence criterion or criteria is reached.
In the distributed-memory parallel version, each process reads a distinct chunk of data, applies the preprocessing steps, and proceeds to calculate the models, as in the serial version. Each model is then responsible for communication between processes to ensure that it is properly fit to the full data set. See Figure 2.
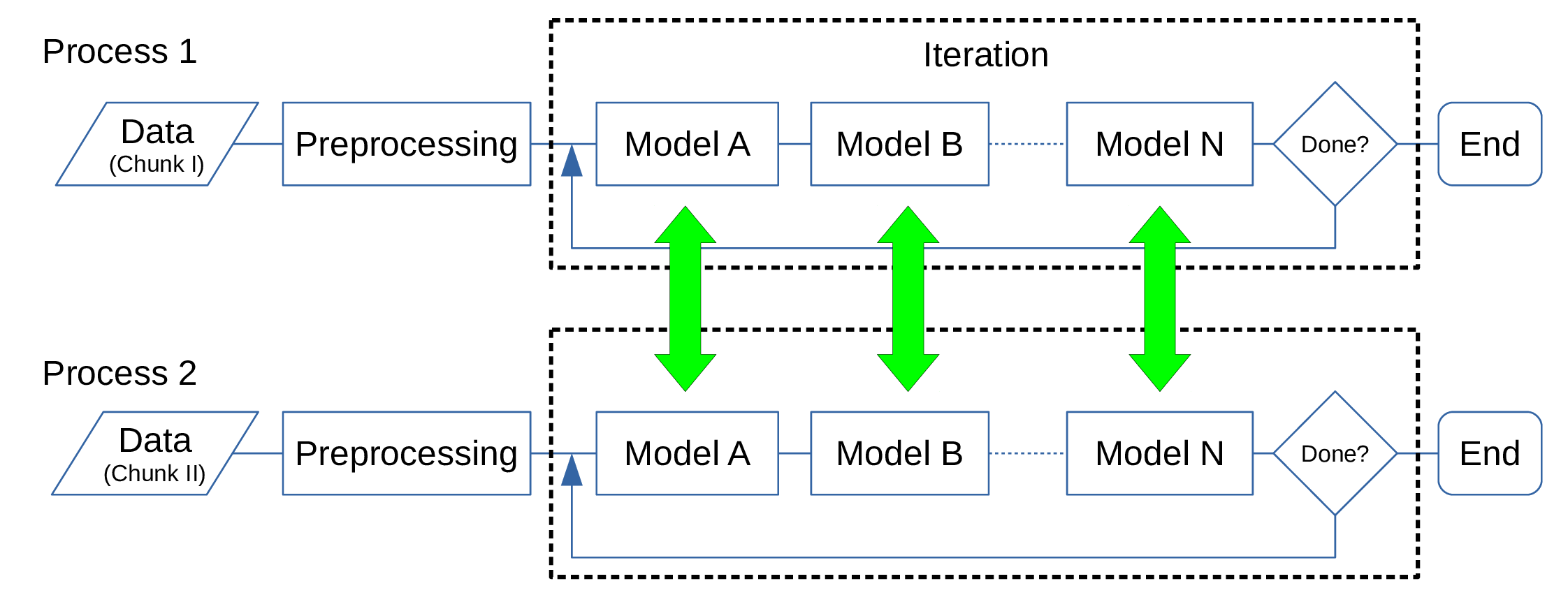
By breaking up the data set over Nnode processes, we are able to handle data sets much larger than can be done with a single machine. Additionally, since the calculations are split up over many nodes, the map-maker can in principle run much faster than the serial version. The speed-up in run time is not simply 1/Nnode, however, due to the time required by the communication steps, which can be significant. Also, since the model calculations proceed sequentially, the system proceeds only as fast as the slowest node. The scaling of run time with number of processes for a prototype of this algorithm has been discussed elsewhere ([4, 6]).
We point out that makemap is already multithreaded using pthreads to take advantage of multi-core CPUs. We intend to implement the distributed-memory parallelization while maintaining the multithreading, as the shared-memory parallelization is much more efficient since there is little communication overhead.