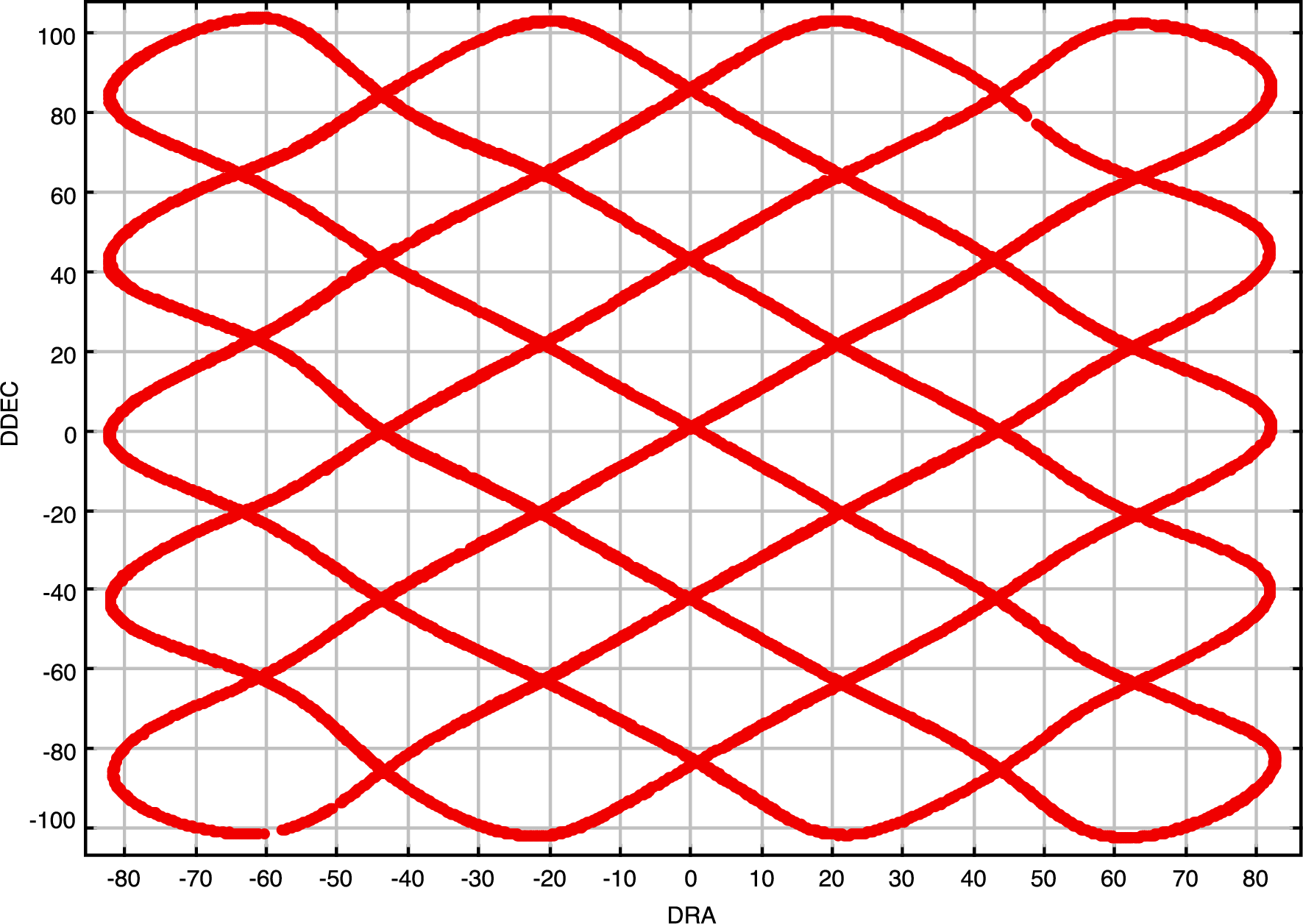
Figure 1: The telescope positions during observation number 7 on 20090107. The plot is created
by Topcat from the output from jcmtstate2cat plotting the DRA columns against the DDEC
column. The pong scan pattern is clearly visible.
This document is aimed at users who wish to perform their own customised reductions of ACSIS or SCUBA-2 data. It is is expected that most users will normally prefer to use the higher level facilities provided by the appropriate Orac-dr pipeline.
The main purpose of this document is to provided complete reference information for all facilities provided by Smurf. Thus, for instance, it contains details of all available command parameters and configuration parameters. It is not really intended to be read from start to finish as a complete document, but rather to be dipped into, as and when needed, for information about specific parameters or facilities. Most users will normally refer to this document during the course of reading the following higher-level documents:
After an introductory section covering the mechanics common to using all Smurf commands, the rest of this document is divided into two main parts; one dedicated to processing ACSIS data ([2], see Section 2) and the other for processing SCUBA-2 data ([4], see Section 3).
In an attempt to make this document clearer to read, different fonts are used for specific structures:
HISTORY).
% smurf), as are command-line parameters for tasks
(which are displayed in upper case - e.g. METHOD).
Smurf is a suite of Starlink ADAM tasks (SUN/101 and SG/4) and therefore requires the Starlink environment to be defined. For C shells (csh, tcsh), do:
before using any Starlink commands. For Bourne shells (sh, bash, zsh), do:
Having set up Starlink as described in the previous paragraph, the Smurf commands are made available by typing smurf at the shell prompt. The welcome message will appear as shown below:
This defines aliases for each Smurf command, gives a reminder of the help command and shows the version number. You can now use Smurf routines or ask for help.
Access the Smurf online help system as follows:
Further help on the help system maybe obtained by accessing the topic smurfhelp from within smurfhelp. If you already know the topic for which you want help, you can access it directly by specifying it on the smurfhelp command line, as in the following example:
If an application prompts you for input and you do not know what the parameter means, you can use ? at the prompt for more information.
Smurf uses named parameters to specify input and output files and other variables necessary for data processing. There are two types of named parameter which should not be confused as they are accessed and specified in very different ways:
Maybe the most difficult aspect of giving ADAM parameter values on the command line is handling shell meta-characters. If the parameter value includes any characters that would normally be interpreted and replaced by the Unix shell before invoking the requested command, such as wild-cards, dollars, commas, etc, then they must be protected in some way so that the Starlink software receives them unchanged. This can be done either by escaping each meta-character (i.e. preceding each one with a back-slash character - “\”) or by quoting the whole string. If all else fails, it may be necessary to enclose the parameter value in two layers of quotes, an inner layer of single quotes and an outer layer of double quotes. Note, the above comments only apply for ADAM parameter values that are supplied on the command line - when supplying a value in response to a prompt, ths Unix shell is not involved and so shell meta-characters should not be escaped or enclosed in quotes.
CONFIG”. The configuration parameter settings
can be specified directly as a comma separated list in response to a prompt for CONFIG, or
may be stored in a text file, the name of which is then supplied (preceded by a caret - ‘^’)
when prompted for CONFIG. Each Smurf command that requires a group of configuration
parameters will document what is needed, and how it can be supplied, in the reference
documentation for CONFIG. Appendix E describes individual configuration parameters in
detail. Kappa (SUN/95) has a complete description of the various ways in which groups
can be specified.All Smurf commands support the ‘message filter’ ADAM parameter (MSG_FILTER), which
controls the number of messages Smurf writes to the screen when executing routines. The
default setting for the message filter is normal. Table 1.2.4 lists the available values for
MSG_FILTER. Be aware that specifying verbose or debug will slow down execution due to the
(potentially vast) number of messages written to the terminal. It is also possible to control
message output by setting the MSG\_FILTER environment variable to one of the values
listed in this table. To hide all messages, a quick option is to add QUIET to the command
line.
| Option | Description |
| none | No messages |
| quiet | Limited messages |
| normal | Very few messages |
| verbose | Full messages |
| debug | Some debugging messages (useful for programmers) |
| all | All messages regardless of debug level |
Smurf does not itself enforce a naming scheme on files. However, raw data from ACSIS and SCUBA-2 obey a well-defined naming scheme. The convention is as follows: the name is composed of an instrument prefix, the UT date in the form YYYYMMDD, a zero-padded five-digit observation number, followed by a two-digit sub-system number (ACSIS only) and a zero-padded four-digit sub-scan number, all separated by underscore characters. The file has an extension of .sdf. The instrument prefix for ACSIS is simply “a”. For SCUBA-2 it is a three-character string dependent on the particular sub-array from which the data were recorded. The SCUBA-2 sub-arrays are labelled a–d at each wavelength, which are coded by a single digit (either 4 or 8 for 450 and 850 m data respectively); thus the SCUBA-2 prefix is s[4|8][a-d].
Example ACSIS file name: a20090620_00023_01_0002.sdf
Example SCUBA-2 file name: s8a20090620_00075_0001.sdf
Files can be processed either singly or in batches. It is more efficient to process multiple files at the same time. There are three ways to specify multiple files:
IN.
For more information on specifying groups of objects for input and output, see the section Specifying Groups of Objects in the Kappa documentation (SUN/95). Examples of valid inputs (including the back-slashes and quotes required to protect the shell meta-characters) are:
Note that if you are providing a text file containing output file names, those should be listed in the same order as the input file names, otherwise the processed data will be written under the wrong file names.
Data files for both ACSIS and SCUBA-2 [6] use the Starlink N-dimensional Data Format (NDF, see NDF), a hierarchical format which allows additional data and metadata to be stored within a single file. The KAPPA Kappa (SUN/95) contains many commands for examining and manipulating NDF structures. A single NDF structure describes a single data array with associated meta-data. NDFs are usually stored within files of type “.sdf”. In most cases (but not all), a single .sdf file will contain just one top-level NDF structure, and the NDF can be referred to simply by giving the name of the file (with or without the “.sdf” prefix). In many cases, a top-level NDF containing JCMT data will contain other “extension” NDFs buried inside them at a lower level. For instance, raw files contain a number of NDF components which store observation-specific data necessary for subsequent processing. The contents of these (and other NDF) files may be listed with Hdstrace. Each file holding raw JCMT data on disk is also known as a ‘sub-scan’.
The main components of any NDF structure are:
For ACSIS, the raw data are stored as , while SCUBA-2 data are stored as , where is the number of time samples in a file.
The files also contain additional NDF components common to both instruments:
The jcmtstate2cat command can be used to extract the time varying metadata and store it in a tab-separated table (TST) format catalogue.1 so that it can be visualised using Topcat. An example Topcat plot of the telescope motion for a particular observation can be seen in 1. The JCMTSTATE extension contains information from the telescope, secondary mirror and real-time sequencer (RTS). ACSIS observations include environmental weather information and SCUBA-2 observations include SCUBA-2 data (such as the mixing chamber temperature) and the water vapour monitor (WVM) raw data. jcmtstate2cat converts the telescope and SMU information to additional columns showing the tracking and AZEL offsets and also converts raw WVM data to a tau (CSO units). Finally, SCUBA-2 data has additional low-level MCE information that can be included in the output catalogue using the ‘--with-mce‘ option.
The original XML used to specify the details of the observation can be obtained from any data file using the dumpocscfg command.
The FITS extension is used to store information that either does not change or changes by a small amount during the course of an observation. Note that in the particular case of SCUBA-2 data some values in the FITS extension will change for each sub-scan (i.e. file) of a single observation. The values in the FITS extension may be viewed with the Kappa fitslist command.
Each instrument has further specific components. SCUBA-2 files contain dark SQUID data, the current flatfield solution, an image of the bolometers used for heater tracking and possibly information indicating how to uncompress the raw data. ACSIS files contain information about the receptors used including their coordinates in the focal plane.
Output files created by Smurf may contain some or all of these, plus new components with
information about the output data. These are noted in the description of specific applications. All
output files contain a PROVENANCE extension which provides a detailed record of the data processing
history. Use the Kappa command provshow to list the contents.
Smurf uses AST for its astrometry and thus any coordinate system supported by AST may be used
when creating images/cubes. The default behaviour is to use the system in which the observations
were made (known as the TRACKING system within Smurf).
The mapping tasks makemap and makecube automatically deal with moving sources. There is no need to deal with moving sources explicitly for any processing with Smurf. Maps and cubes made from moving sources will use a coordinate system that represents offsets from the source centre, rather than absolute celestial coordinates.
Be aware that the raw data files from both instruments may be large (tens to hundreds of megabytes). Subsequent processing of raw SCUBA-2 time-series data produces output files which are even larger for two reasons:
Thus file size increases in the range 4 to 6 are to be expected. Smurf mapping tasks have the ability to
restrict the size of output data files for manipulation on 32-bit operating systems. For further details,
see the description of the TILEDIMS parameter in the sections on makemap and makecube.
Processing SCUBA-2 data is faster on 64-bit systems due to its use of double precision for all
calculations.
1This is a standard format historically supported by Cursa and ESO SkyCat
2This uncompression is performed automatically when the data is read by any Starlink command - there is no need to uncompress the data as a separate step.